For everyone of us who wakes and codes everyday somewhere in this world, we often find ourselves pretty attached to the programming language we love most. All of us feels that point of idiosyncrasy when we try to break our boundaries and try to learn something new since this field is always expanding and evolving like a universe on steroids.
For those who still are newbies and is trying to find ways to understand how a programming language works, what could be better than trying to make one of your own? 🙂 This post is essentially a small proof of concept where we will go for a small nice fun looking esoteric programming language.
Before we jump into the very tidbits inside, allow me to explain what we will do here. We will write a small programming language that is parsed and lexed by ANTLR, transpiles to C# and the transpiled code is fed into Roslyn C# script api.
If the aforementioned words are looking too wordy for you, let me clear it right up for you. Like every language we use to talk every day, programming language comes with a grammar itself. It should be clear as a daylight to you if you have written a single line of code in your life. Every programming language follows a pretty defined structure and a dancing parade of words following that. So, since we are creating one, the first thing we need is that grammar for our language. Instead of doing it from scratch, our tool of choice is ANTLR, which stands for “Another Tool for Language Recognition”. ANTLR will help us to define the grammar, generate the lexer and parser for it and we will eventually be able to reuse those components to transpile our code to C#. Remember ANTLR do support for javascript, java, python too. So, if you want to have your lexer and parser defined in those languages, please don’t refrain yourself from using this.
Now, even before we start talking about languages and everything else, we need to understand a bit about compiler theory. Now, I can go into gory details of lexer and parser but since this is an age of google, I will let that responsibility fall in your hand. We will take somewhat of an exploratory way to understand how everything works and take it from there.
Let’s assume that we have a language like this:
derp a = 20 ':)' #Initialization
# basic if-else
a > 2 ???
yep ->
a = 5 ':)'
kbye
# print
dump a ':)'
The first thing we need is a grammar. To understand the programming language we need something that understands all the words here. And that guy is the lexer. A lexer eats up the whole code block we send to the compiler, chops that into little lexemes (read strings/words here). So we can understand when we have hit a specific keyword. Like for our dummy language here, we used the popular internet lingo derp to initialize a variable.
The next thing in line to do is making some meaningful excerpt from the words. Like when we write a if block, the compiler needs to know what strings of characters or words should stand together to construct a meaningful statement or expression. That is the job of a parser. If you see closely, you will see that every block of code can be expressed as a tree. For example, the initialization block here looks like the following:

This is definitely a single branch tree, it says you need to write the word derp to start the statement and you should end it with a smiley ( 🙂 ) to finish the statement. In the middle you use an identifier (name for your variable) and an ASSIGN operator (=) to define the flow of assignment from right to left. That tree is actually generated straight from the grammar we are going to use today.
So, why wait? Let’s have a look at the grammar we are going to be using today:
grammar Profane;
compilationUnit: statement* EOF;
statement:
printstmt
| assignstmt
| ifstmt
| setstmt;
printstmt : 'dump' expr? SMILEY;
assignstmt : 'derp' ID ASSIGN expr SMILEY;
setstmt : ID ASSIGN expr SMILEY;
ifstmt :
conditionExpr '???'
'yep ->'
statement*
'kbye';
conditionExpr: expr relop expr;
expr: term | opExpression;
opExpression: term op term;
op: PLUS | ASSIGN | MINUS;
relop: EQUAL | NOTEQUAL | GT | LT | GTEQ | LTEQ;
term: ID | number | STRING;
number: NUMBER;
// Keywords
ID: [a-zA-Z_] [a-zA-Z0-9_]*;
SMILEY: ':)';
WS: [ \n\t\r]+ -> skip;
PLUS :'+';
EQUAL : '====';
ASSIGN : '=';
NOTEQUAL: '!!==';
MINUS : '-';
GT : '>';
LT : '<';
GTEQ : '>=';
LTEQ : '>=';
fragment INT: [0-9]+;
NUMBER: INT ('.'(INT)?)?;
STRING: '"' (~('\n' | '"'))* '"';
Now, my first advice here will be to not get confused by the size of the grammar and start taking out bits we do understand at first. If you refer to the first image in this and have a look at the grammar you will see that the rule assignstmt is defined the exact same way depicted in the picture. If you find the words ID, ASSIGN and SMILEY, you will also see that all of them are defined in the grammar below where they have their literal form. These tokens helps the parser to understand what you have written. And the assignstmt is called a rule, which define relations among different tokens or rules. See? this is how we build rules for our grammar. Because a grammar is nothing but a set of well defined rules.
By the very first rule named compilationUnit,our language is nothing but a set of statements ending with an EOF. Every statement can either be a printstmt (for printing), ifstmt (if-else) or the aforementioned assignstmt. Neat huh? You can even go down and find out how the rest of the tree is built.
I strongly suggest using Visual Studio Code and its ANTLR4 extension for writing ANTLR grammar files. You will have nice looking railroad diagram like the one I posted for every rule you write!
Time to get our hands dirty. Fret not since the whole project is publicly available over github so I will only point out excerpts of the code that we need to visit. And I’m going back to the same assignstmt. First thing we need to do is download ANTLR . Go to the download page and download the latest .jar. ANTLR is written in Java so you will need to have java installed in your machine. We will use .net core here for the rest of the work so you can download that for your OS too. When you are done downloading ANTLR you can generate the target code for C# from your grammar file. In our case the grammar file name was Profane.g4 and to generate the C# lexer and parser based off the code all we had to do is invoke :
java -jar antlr-4.7-complete.jar -Dlanguage=CSharp Profane.g4
It will generate the C# classes you need for walking through the grammar. You will see a lexer and a listener class being created. You don’t really need to touch the lexer class. The listener class is used to handle events that are fired when ANTLR encounters a rule. So, to make use of our assignment statement we need to handle the event that is fired when ANTLR encounters our assignstmt rule. But how will we ever understand which event is that? Here comes the ANTLR magic.
ANTLR will generate the event you need for all your rules every time you create a lexer and parser from your grammar. That means every time you change your grammar you need to regenerate the C# targets again, the lexer and listener class. I added the command in the build target for the sample project so it will automatically do it on build.
So, lets create a class inherited from ProfaneBaseListener class which was auto generated by ANTLR and name it ProfaneListener. Since our rule was named assignstmt ANTLR will generate a method called EnterAssignstmt inside it which will be invoked every time ANTLR encounters that type of statement or that rule. Our target here is to generate equivalent C# code from it so
derp some = 10 ':)'
will be transpiled in C# equivalent code like the following.
dynamic some = 10;
And we are going to do that in the method EnterAssignstmt which ANTLR has built out for us. Let’s have a look at it.
public override void EnterAssignstmt([NotNull] ProfaneParser.AssignstmtContext context)
{
string target = context.ID().GetText();
dynamic value = this.ResolveExpression(context.expr());
this.Output += "dynamic " + target + " = " + value + ";\n";
}
This is really simple work here. We are asking the context class to give us the ID and the expression so we can generate the equivalent C# code string. The nice thing you can notice here is ANTLR has generated class for our assignment statement context itself. But what is that ResolveExpression method. If we remember the rule it was :
Here expr is another rule. Which looks like.

That means, expr can either be a rule named term or a rule named opExpression. Let’s have a look at both of them.
First is the rule called term. A term can be an identifier (the name for your variable), a number (int or float) or a string. Either one of these.
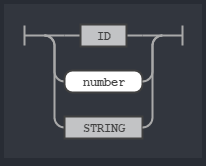
That means that term can also be a valid value for rule expr. Since expr is either term or opExpression
The opExpression on the other hand is a tad complex one. This is an example where you can reuse multiple rules to create a complex rule.
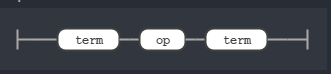
The only thing that we don’t know here is the op rule. the opExpression rule says it is structured as term followed by a rule named op and there has to be another term in the end.
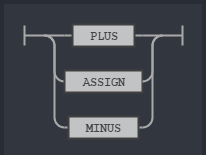
The op rule defines an OR relationship between PLUS, MINUS and ASSIGN which stands respectively for ‘+’, ‘-‘ and ‘=’. That means this rule says we can write things like
derp some = 10 + 2 + someOtherDerp 🙂
Amazing! Isn’t it?
Before we look into the ResolveExpression method, let’s see a nice looking tree on how that previous statement actually gets parsed by all these rules.
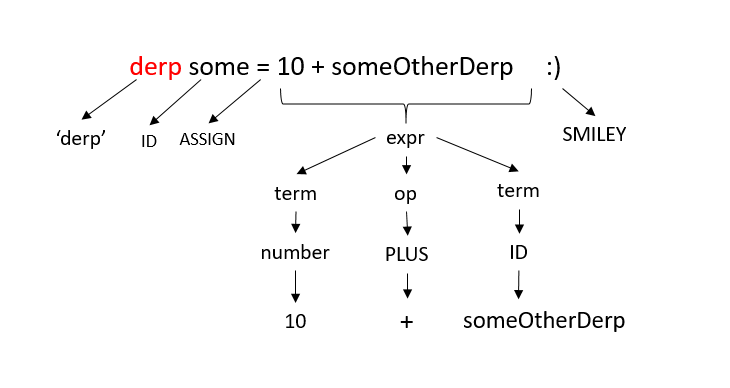
This will hopefully help you to understand how things are happening here. Now, lets see the ResolveExpression method which transpiles the rule expr.
private dynamic ResolveExpression(ProfaneParser.ExprContext exprContext)
{
var opExpression = exprContext.opExpression();
if (opExpression != null)
{
return ResolveOpExpression(opExpression);
}
else
{
return ResolveTerm(exprContext.term());
}
}
private dynamic ResolveOpExpression(ProfaneParser.OpExpressionContext plusContext)
{
var leftTerm = plusContext.term().First();
var rightTerm = plusContext.term().Last();
var left = ResolveTerm(leftTerm);
var right = ResolveTerm(rightTerm);
return left + plusContext.op().GetText() + right;
}
private dynamic ResolveTerm(ProfaneParser.TermContext termContext)
{
if (termContext.number() != null)
{
return termContext.number().GetText();
}
else if (termContext.ID() != null)
{
return termContext.ID().GetText();
}
else if (termContext.STRING() != null)
{
Regex regex = new Regex("/\\$\\{([^\\}]+)\\}/g");
var contextText = termContext.GetText();
var replacedString = regex.Replace(contextText, "$1");
return replacedString;
}
else return default(dynamic);
}
We also see two new methods the ResolveExpression method uses named ResolveTerm and ResolveOpExpression. They generate the transpiled C# code for term rule and opExpression rule. We keep adding the generated code in a string named output and when it’s done we have our C# transpiled code ready to be executed.
Executing C# as a script using Roslyn:
Now that we have our C# code to be executed, we will use another tool called Roslyn. It is a compiler tool for .net that gives you rich set of features regarding code analysis and compilation. We will specifically be using the C# scripting api.
First we need to generate the AST for our code. If you are scratching head on what an abstract syntax tree is, you already saw something like it in the tree we posted before. To generate the tree, you need your lexer. Your lexer will generate tokens. Your parser will use those tokens to start the execution unit you need to compile your code which is the root node for your tree. This is still done using ANTLR.
When you have your tree, you need to walk on it. When you walk on the AST, the listener fires the events we need to generate the transpiled code like we did minutes ago. So the listener output is our C# code which we need to feed to roslyn.
Roslyn C# script engine comes with a nifty class named CSharpScript which will do the trick for you. All we have to do is to feed the C# code and load the assemblies we will need. Then, it will do its magic and we will have our own scripting language talking to us.
So, our transpiler class looks like
public class ProfaneTranspiler
{
private ProfaneListener listener;
private static readonly MetadataReference[] References =
{
MetadataReference.CreateFromFile(typeof(object).GetTypeInfo().Assembly.Location),
MetadataReference.CreateFromFile(typeof(RuntimeBinderException).GetTypeInfo().Assembly.Location),
MetadataReference.CreateFromFile(typeof(System.Runtime.CompilerServices.DynamicAttribute).GetTypeInfo().Assembly.Location),
MetadataReference.CreateFromFile(typeof(ExpressionType).GetTypeInfo().Assembly.Location),
MetadataReference.CreateFromFile(Assembly.Load(new AssemblyName("mscorlib")).Location),
MetadataReference.CreateFromFile(Assembly.Load(new AssemblyName("System.Runtime")).Location)
};
public ProfaneTranspiler()
{
this.listener = new ProfaneListener();
}
public ProfaneParser.CompilationUnitContext GenerateAST(string input)
{
var inputStream = new AntlrInputStream(input);
var lexer = new ProfaneLexer(inputStream);
var tokens = new CommonTokenStream(lexer);
var parser = new ProfaneParser(tokens);
parser.ErrorHandler = new BailErrorStrategy();
return parser.compilationUnit();
}
public string GenerateTranspiledCode(string inputText)
{
var astree = this.GenerateAST(inputText);
ParseTreeWalker.Default.Walk(listener, astree);
return listener.Output;
}
public async Task&amp;amp;amp;lt;TranspileResult&amp;amp;amp;gt; RunAsync(string code)
{
var result = new TranspileResult();
if (string.IsNullOrEmpty(code))
return result;
Stopwatch watch = new Stopwatch();
watch.Start();
try
{
ScriptOptions scriptOptions = ScriptOptions.Default;
scriptOptions = scriptOptions.AddReferences(References);
scriptOptions = scriptOptions.AddImports("System");
var resultCode = this.GenerateTranspiledCode(code);
if (resultCode == null)
{
watch.Stop();
result.TimeElapsed = watch.Elapsed.ToString();
return result;
}
var outputStrBuilder = new StringBuilder();
using (var writer = new StringWriter(outputStrBuilder))
{
Console.SetOut(writer);
var scriptState = await CSharpScript.RunAsync(resultCode, scriptOptions);
result.output = outputStrBuilder.ToString();
}
}
catch (Exception ex)
{
result.output = ex.Message;
}
finally
{
watch.Stop();
result.TimeElapsed = watch.Elapsed.ToString();
}
return result;
}
}
I uploaded the full sample code in github here. You need to build and run the Profane project which is a console app. It will host a small web api in port 5000. If you POST your code to the endpoint as plain text in the POST body, you will get back the output of your code. Postman can be a nice client to do so.
Hope this was fun. Knowing the internals of your daily programming language essentially boosts up the confidence while you write it. So make your own esoteric language if you have time. It’s always fun to make em.

One thought on “Creating a nano scripting language using ANTLR and Roslyn”